원문 보기: What is adversarial machine learning?
아래의 두 사진은 인간이 보았을 때는 똑같은 사진이다. 그러나 구글의 연구원들이 2015년에 공개한 사물 감지 알고리즘은 왼쪽 사진은 “팬더”, 오른쪽 사진은 “긴팔원숭이”로 분류하였다. 그리고 이상하게도, 알고리즘은 긴팔원숭이로 분류한 사진에 더 큰 확신을 가지고 있었다.
이 알고리즘에 사용된 머신러닝은 2014년 이미지넷에서 주관한 이미지 인식 대회(ILSVRC 2014)에서 우승을 차지한 컨볼루션 신경망 구조의 구글넷(GoogLeNet)이다

Adversarial examples fool machine learning algorithms into making dumb mistakes
오른쪽의 사진은 “적대적 예제”이다. 인간의 눈에 띄지 않는 미묘한 조작을 거친 사진으로, 기계 학습 알고리즘은 왼쪽의 사진과 오른쪽의 사진을 완전히 다르게 인식한다.
적대적 예제들은 인공지능 알고리즘의 작동을 방해한다. 지난 몇 년 동안 AI의 역할이 지속적으로 증가함에 따라 적대적 머신 러닝에 대한 연구 또한 활발히 이루어지기 시작했다. 이에 따라 머신 러닝의 취약점이 악용될 수 있다는 우려도 생겨났다.
연구를 통해 거북이를 소총으로 착각하는 것과 같은 재미있고, 온순하며 당황스러운 예제들부터 정지 신호를 속도 제한으로 오인하는 위험할 수 있는 예제들도 존재한다는 것이 드러났다.

Researchers at labsix showed how a modified toy turtle could fool deep learning algorithms into classifying it as a rifle (source: labsix.org)
기계 학습이 세상을 보는 방식
적대적 예제가 어떻게 만들어지는지 알아보기 전에 먼저 기계 학습 알고리즘이 이미지와 비디오를 분석하는 방법을 이해해야 한다. 이 글의 첫 부분에서 언급한 것과 같은 이미지 분류 인공지능을 생각해보자.
기계 학습 모델은 기능을 수행하기 전에 수많은 라벨링이 된 이미지(판다, 고양이, 개, 등등)를 통해 “학습”단계를 거친다. 모델은 각 이미지의 픽셀을 분석하고 각 이미지를 관련 라벨과 연결할 수 있도록 많은 내부의 변수를 조정한다. 학습이 끝나면 모델은 학습되지 않은 이미지에도 적절한 라벨을 달 수 있어야 한다. 쉽게 말해 기계 학습 모델은 픽셀 값을 입력으로 받고 해당 이미지의 라벨을 출력하는 수학적 함수라고 생각할 수 있다.
기계 학습 알고리즘 모델 중 하나인 인공 신경망은 그림, 소리, 문서와 같이 지저분하고 체계적이지 않은 데이터를 처리하는 데 특히 적합하다. 인공 신경망에는 변수가 많고 데이터의 다양한 패턴에 유연하게 대처할 수 있기 때문이다. 쌓여진 데이터의 양이 많은 신경망은 분류와 예측을 할 수 있는 능력이 비교적 높은데, 이러한 신경망을 “심층 신경망”이라고 부른다.
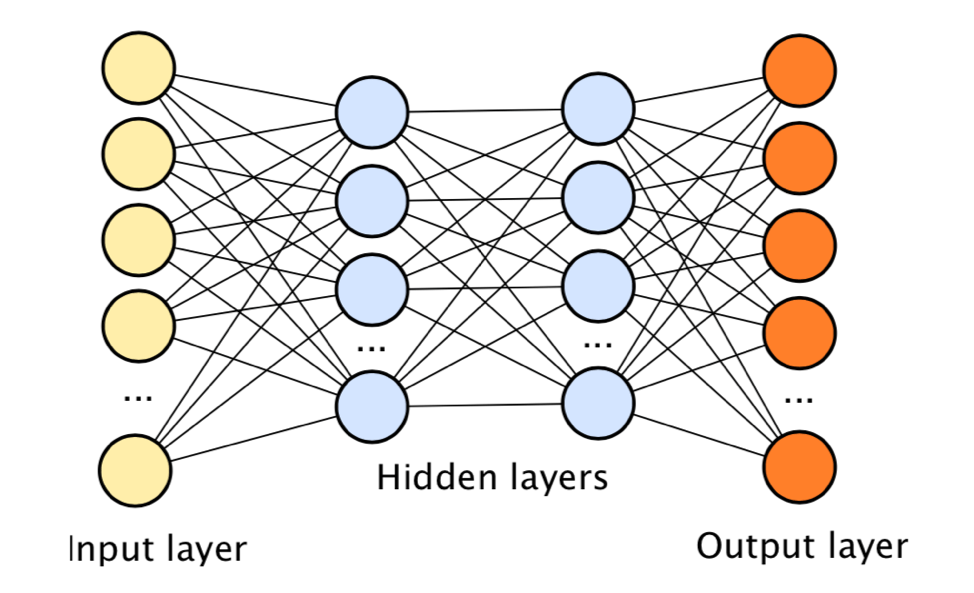
Deep neural networks are composed of several stacked layers of artificial neurons
신경망을 사용하는 기계 학습 중 하나인 딥 러닝은 현재 인공지능 연구의 최첨단 분야이다. 딥 러닝 알고리즘은 컴퓨터 비전 및 자연어 처리와 같이 최근에 한계를 넘어선 업무를 수행할 때 적합하다.
그러나 우리는 딥 러닝 및 머신 러닝 알고리즘이 숫자 처리에 뛰어나다는 점에 주목할 필요가 있다. 딥 러닝 알고리즘은 픽셀 값, 단어의 순서, 음파에서 미묘하고 복잡한 패턴을 인간과는 다른 방식으로 찾아낼 수 있다.
이 과정에서 적대적 예제들이 나타나는 것이다.
적대적 예제가 생기는 이유
사람들에게 무엇을 통해 사진에 있는 것이 판다인지 알았냐고 물어보면 사람들은 둥근 귀, 눈 주변의 검은색 반점, 주둥이, 복슬복슬한 털을 말할 것이다. 더 나아가 팬더의 서식지나 취하는 포즈와 같은 것들도 얘기할 수 있을 것이다.
반면에 인공 신경망은 방정식으로 구한 픽셀에 대한 값을 통해 사진에 있는 것이 팬더라고 판단한다. 다시 말해 픽셀 값을 조정하는 것으로 인공지능이 팬더가 아닌 다른 것으로 판단하도록 속일 수 있는 것이다.
본문의 시작 부분에서 언급했던 적대적 예제의 경우 인공지능 연구원은 기존의 판다 사진에 미세한 잡음을 추가하였다. 이 잡음은 인간의 눈으로는 감지할 수 없는 것이다. 그러나 이는 픽셀 값을 바꾸었고, 새로운 픽셀 값이 신경망을 통과하여 판다를 긴팔원숭이로 판단하게 된 것이다.
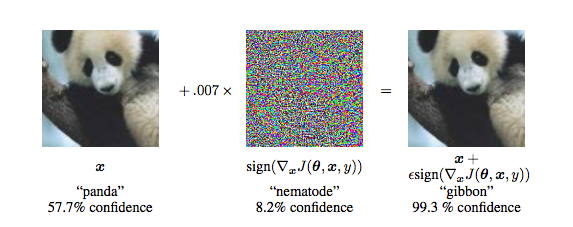
Adding a layer of noise to the panda image on the left turns it into an adversarial example
적대적 기계 학습을 만드는 것은 기계 학습 시행착오 과정이다. 대부분의 이미지 분류 모델은 신뢰 수준과 함께 예측 결과를 제공한다( 판다 90%, 긴팔원숭이 50%, 곰 15%). 적대적 예제를 만드는 것을 통해 미세한 픽셀 값 조정이 신뢰 수준에 어떤 영향을 미치는지 확인할 수 있다. 픽셀 값의 충분한 조정을 통해 어떤 잡음이 어떤 예측 결과의 신뢰 수준을 향상시키는 지를 정리한 지도를 만들 수 있다. 이 과정은 대부분 자동으로 진행된다.
지난 몇 년간 적대적 예제를 통한 기계 학습의 효과에 대한 광범위한 연구가 진행되었다. 2016년 카네기 멜론 대학의 연구원들은 특수 안경을 착용하는 것이 얼굴 인식 신경망이 사람을 연예인으로 착각하게 만들 수 있음을 알아내었다.

Researchers at Carnegie Mellon University discovered that by donning special glasses, they could fool facial recognition algorithms to mistake them for celebrities (Source: http://www.cs.cmu.edu)
또한 삼성과 워싱턴 대학교, 미시간 대학교, UC 버클리 대학의 연구원들은 표지판 사진을 약간만 조정하면 자율 주행 자동차의 컴퓨터 비전 알고리즘이 표지판을 인식하지 못하는 것을 발견하였다. 어쩌면 해커는 이를 이용하여 자율 주행 자동차가 사고를 유발하게 할 수도 있을 것이다.

AI researchers discovered that by adding small black and white stickers to stop signs, they could make them invisible to computer vision algorithms (Source: arxiv.org)
문서와 음성 데이터에서 나타나는 적대적 예제들
적대적 예제의 발생은 시각적 데이터에 국한되지 않는다. 문서 음성 데이터에서도 적대적 예제들이 발견되어 관련 연구가 진행되었다.
2018년 UC 버클리 대학의 연구원들은 적대적 예제를 통해 자동 음성 인식 시스템 (ASR)의 작동을 조작하는 데 성공했다. 아마존의 알렉사, 애플의 시리, 마이크로소프트의 코타나와 같은 음성 인식 서비스는 모두 ASR을 사용하여 음성 명령을 인식한다.
예를 들어 유튜브에 게시된 노래를 재생하여 근처 스마트 스피커에 음성 명령이 입력되도록 수정할 수 있다. 인간이 모르게 음성 인식 알고리즘을 소리 속 숨겨진 명령어를 듣고 실행시킬 수 있는 것이다.
2019년 아이비엠(IBM), 아마존, 텍사스 대학의 연구원들은 스팸 필터 같은 문서를 분류하는 기계 학습 알고리즘을 속일 수 있는 적대적 예제를 만들었다. 텍스트 문서 처리 과정에서 나타나는 적대적 예제는 “문장재구성 공격”이라고도 불리는데, 이는 글에서 단어의 순서를 수정하여 인간이 보았을 때에는 이상이 없지만 알고리즘이 보았을 때 오류를 유발한다.

Examples of paraphrased content that force AI algorithms to change their output
적대적 예제들로부터 안전해지는 방법
기계 학습 모델을 적대적 예제로부터 보호하는 방법 중 하나는 “적대적 예제 훈련”이다. 적대적 예제를 통해 기계 학습 알고리즘을 학습하여 기계 학습 알고리즘이 데이터의 미묘한 변화에 대해 견고하게 만들어 주는 것이다.
그러나 적대적 예제 훈련은 비용이 많이 들고 시간이 오래 걸린다. 모든 예제 각각이 야기하는 약점을 조사한 다음 해당 예제로 모델을 다시 훈련해야 하기 때문이다. 연구원들은 기계 학습 모델에서 적대적 약점을 발견하고 이를 패치하는 과정을 최적화하는 방법을 개발하고 있다.
동시에 인공지능 연구원들은 더 높은 수준에서 딥 러닝 시스템의 적대적 취약성을 해결할 수 있는 방법을 찾고 있다. 한 가지 방법은 신경망들을 병렬로 결합한 다음 무작위로 하나의 신경망을 사용하는 방식으로 이 방식은 적대적 예제들에 대해 기계 학습 알고리즘을 더욱 견고하게 만든다. 다른 한 가지 방법은 여러 개의 신경망으로 하나의 일반화 된 신경망을 만드는 것이다. 이렇게 만들어진 신경망은 적대적 예제에 속을 확률이 비교적 낮을 것이다.
적대적 예제는 인공지능과 인간의 마음이 얼마나 다른지를 분명하게 보여준다.





![[챗봇 활용 2] AI와 ‘진짜 대화’하고 있나요](https://datacdn.soyo.or.kr/wcont/uploads/2025/03/31134049/0_%E1%84%83%E1%85%A2%E1%84%92%E1%85%AA_%E1%84%85%E1%85%A9%E1%84%87%E1%85%A9%E1%86%BA_620.png)




![[챗봇 활용_1] 거꾸로 상호작용](https://datacdn.soyo.or.kr/wcont/uploads/2025/03/09075331/0_%E1%84%83%E1%85%A2%E1%84%92%E1%85%AA_2_620.png)














적대적 예제…조심해야겠군요
적대적 예제를 조심하려면 적대적 예제를 훈련해야 하다니..ㅜㅜ